
微服务的灵魂摆渡者——Nacos
Nacos在微服务系统的服务注册和发现领域,势头迅猛是肉眼可见的。在微服务系统中,服务的注册和发现又是一个灵魂的存在。没有注册中心的存在,成百上千服务之间的调用复杂度不可想象。
如果你计划或已经在使用Nacos了,但仅停留在使用层面,那这篇文章值得你一读。
本文我们先从服务发现机制说起,然后讲解Nacos的基本介绍、实现原理、架构等,真正做到深入浅出的了解Nacos。
服务注册与发现
说起Nacos,不得不先聊聊微服务架构中的服务发现。关于服务发现其实已经在微服务之服务发现 | El-12stu's Blog一文中进行了全面的讲解。我们这里再简要梳理一下。
在传统应用中,一个服务A访问另外一个服务B,我们只需将服务B的服务地址和端口在服务A的静态配置文件中进行配置即可。
但在微服务的架构中,这种情况就有所变化了,如下图所示:
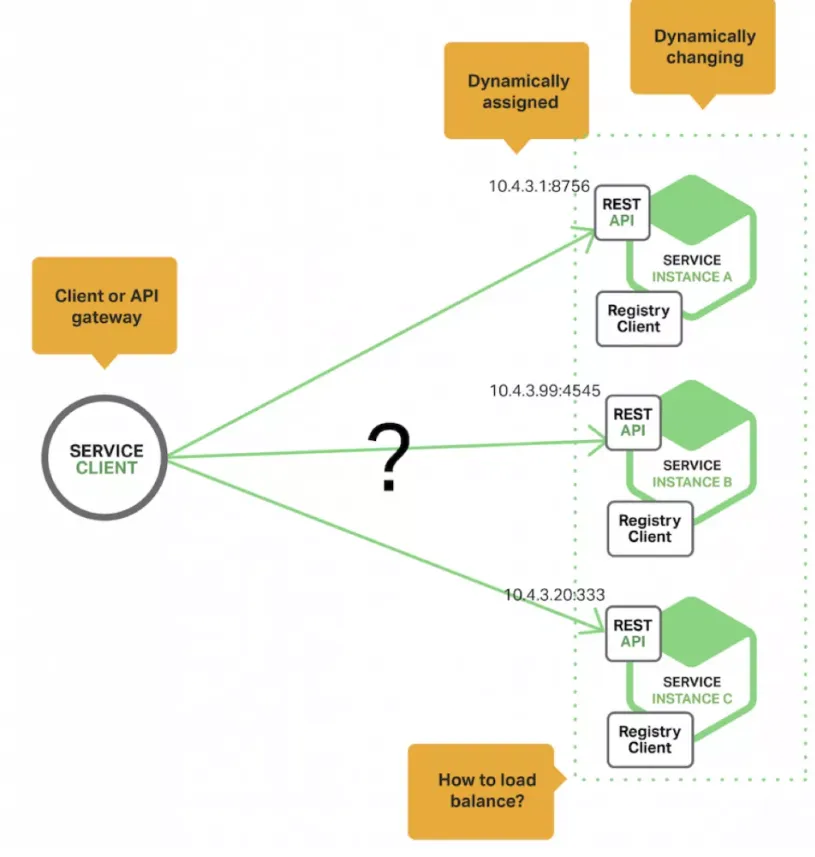
上图中,服务实例的IP是动态分配。同时,还面临着服务的增减、故障、升级等变化。这种情况,对于客户端程序来说,就需要使用更精确的服务发现机制。
为了解决这个问题,于是像etcd、Consul、Apache Zookeeper、Nacos等服务注册中间件便应运而生。
Nacos简介
Nacos一般读作/nɑ:kəʊs/,这个名字来源于“Dynamic Naming and Configuration Service”。其中na取自“Naming”的前两个字母,co取自“Configuration”的前两个字母,而s则取自“Service”的首字母。
Nacos的功能官方用一句话来进行了说明:“一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。”也就是说Nacos不仅提供了服务注册与发现功能,还提供了配置管理的功能,同时还提供了可视化的管理平台。
官方文档中还提到“服务(Service)是Nacos世界的一等公民。”,也就是说在Nacos是围绕着Service转的。
如果查看源码,会发现Nacos的核心API中定义了两个接口NamingService和ConfigService。服务注册与发现围绕着NamingService展开,而配置管理则围绕着ConfigService展开。
官网给出了Nacos的4个核心特性:服务发现和服务健康监测、动态配置服务、动态DNS服务、服务及其元数据管理。我们主要来讲服务发现功能
Nacos的Server与Client
Nacos注册中心分为Server与Client,Nacos提供SDK和openApi,如果没有SDK也可以根据openApi手动写服务注册与发现和配置拉取的逻辑。
Server采用Java编写,基于Spring Boot框架,为Client提供注册发现服务与配置服务。
Client支持包含了目前已知的Nacos多语言客户端及Spring生态的相关客户端。Client与微服务嵌套在一起。
Nacos的DNS实现依赖了CoreDNS,其项目为nacos-coredns-plugin。该插件提供了基于CoreDNS的DNS-F客户端,开发语言为go。
Nacos注册中的交互流程
作为注册中心的功能来说,Nacos提供的功能与其他主流框架很类似,基本都是围绕服务实例注册、实例健康检查、服务实例获取这三个核心来实现的。
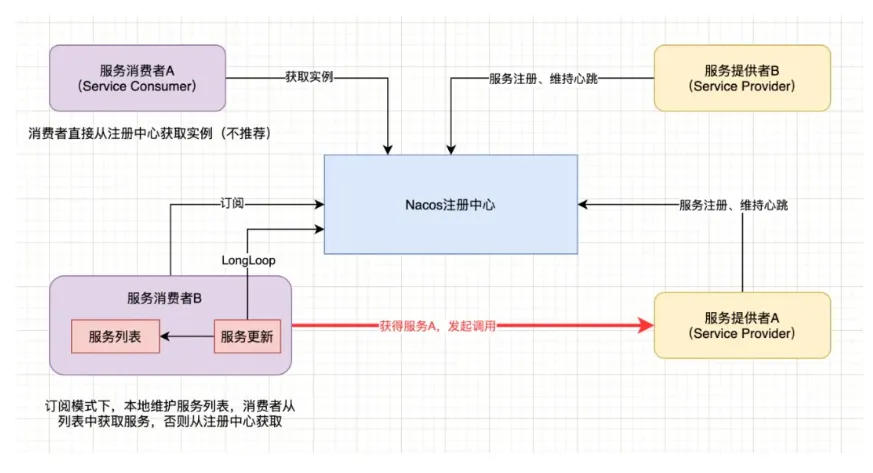
以Java版本的Nacos客户端为例,服务注册基本流程:
- 服务实例启动将自身注册到Nacos注册中心,随后维持与注册中心的心跳;
- 心跳维持策略为每5秒向Nacos Server发送一次心跳,并携带实例信息(服务名、实例IP、端口等);
- Nacos Server也会向Client主动发起健康检查,支持TCP/Http;
- 15秒内无心跳且健康检查失败则认为实例不健康,如果30秒内健康检查失败则剔除实例;
- 服务消费者通过注册中心获取实例,并发起调用;
其中服务发现支持两种场景:第一,服务消费者直接向注册中心发送获取某服务实例的请求,注册中心返回所有可用实例,但一般不推荐此种方式;第二、服务消费者向注册中心订阅某服务,并提交一个监听器,当注册中心中服务发生变化时,监听器会收到通知,消费者更新本地服务实例列表,以保证所有的服务均可用。
好的,我帮你把 **Nacos 服务发现的两种模式(拉模式 vs 推模式)**整理成一个清晰的对比,包括原理、实现、优缺点,让你一眼就能理解。
1. 第一种方式:直接拉取(拉模式 / Request Mode)
1.1 原理
- 消费者每次调用服务时,向 Nacos Server 发起请求,获取指定服务的 所有可用实例。
- 调用完成后,不保留本地缓存,下次调用仍需重新请求。
1.2 实现方式
- 可以直接通过 Nacos OpenAPI 或 SDK 调用:
List<Instance> instances = namingService.getAllInstances("my-service");1.3 优点
- 实现简单,调用直接。
- 不需要维护本地缓存。
- 适合测试或小型系统。
1.4 缺点
- 高延迟:每次调用都要访问注册中心。
- 注册中心压力大:服务调用频繁时,Server 可能成为瓶颈。
- 服务信息滞后:如果服务实例频繁变动,可能拿到过时实例。
2. 第二种方式:订阅 + 监听(推模式 / Subscribe Mode)
2.1 原理
- 消费者在启动时向 Nacos Server 订阅服务,并提供 监听器。
- Nacos Server 在服务实例发生变化时 主动推送通知。
- 消费者将服务实例 缓存到本地,后续调用直接使用本地缓存。
2.2 实现方式
namingService.subscribe("my-service", event -> {
List<Instance> instances = namingService.getAllInstances("my-service");
// 更新本地缓存
});2.3 优点
- 实时性高:服务变化立即通知客户端。
- 注册中心压力小:客户端无需每次调用都请求 Server。
- 可用性高:即使 Server 短暂不可用,本地缓存仍能提供服务。
2.4 缺点
- 实现复杂:需要处理订阅、监听器回调和本地缓存。
- 监听器回调阻塞会影响更新。
- 本地缓存占用一定内存(一般很小)。
3. 对比总结
| 维度 | 拉模式(直接拉取) | 推模式(订阅 + 监听) |
|---|---|---|
| 调用方式 | 每次调用都请求注册中心 | 首次订阅后由 Server 推送更新 |
| 本地缓存 | 无 | 有,本地维护最新服务列表 |
| 实时性 | 低,可能拿到过时实例 | 高,变化立即通知 |
| 注册中心压力 | 高 | 低 |
| 开发复杂度 | 低 | 较高,需要处理监听器和缓存 |
| 推荐场景 | 测试、小型系统 | 生产环境、高并发微服务 |
一句话理解:
- 拉模式:每次问注册中心“谁在线”,简单但压力大。
- 推模式:注册中心主动通知客户端“服务变化了”,高效、实时、生产环境推荐。
Nacos数据模型
关于数据模型,官网描述道:Nacos数据模型的Key由三元组唯一确定,Namespace默认是空串,公共命名空间(public),分组默认是DEFAULT_GROUP。
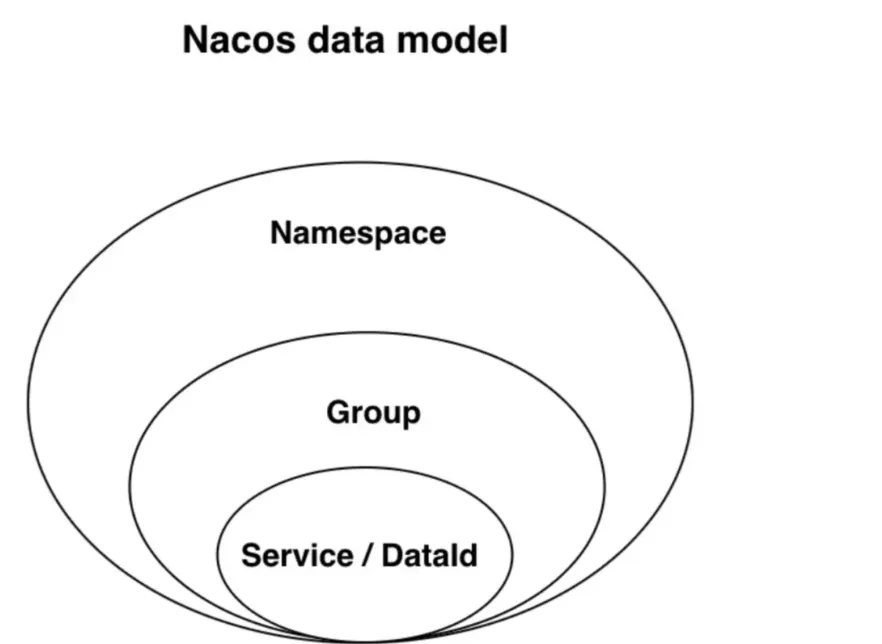
上面的图为官方提供的图,我们可以进一步细化拆分来看一下:
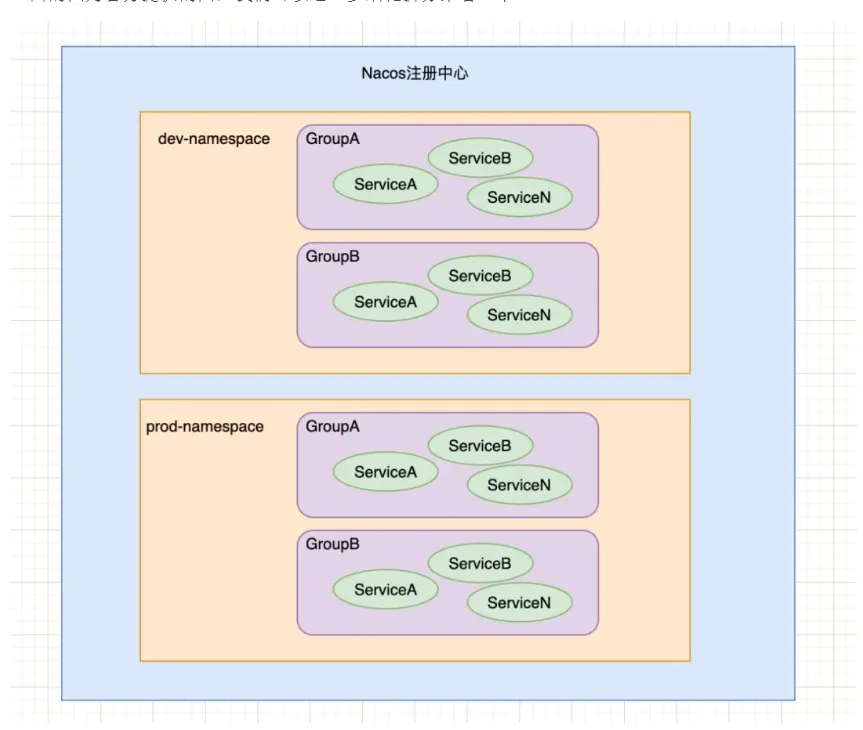
如果还无法理解,我们可以直接从代码层面来看看Namespace、Group和Service是如何存储的:
/**
* Map(namespace, Map(group::serviceName, Service)).
*/
private final Map<String, Map<String, Service>> serviceMap = new ConcurrentHashMap<>();也就是说Nacos服务注册表结构为:Map<namespace, Map<group::serviceName, Service>>。
Nacos基于namespace的设计是为了做多环境以及多租户数据(配置和服务)隔离的。如果用户有多套环境(开发、测试、生产等环境),则可以分别建三个不同的namespace,比如上图中的dev-namespace和prod-namespace。
好的,我来详细说明 Nacos 的 Namespace、Group、Service 三个概念,并用具体例子帮助理解。
1. Namespace(命名空间)
1.1 概念
- 作用:隔离环境或业务线,用于把服务和配置分组管理。
- 一个 Nacos 实例可以有多个 Namespace,每个 Namespace 相互独立。
- 常用场景:
- 不同环境隔离(
dev、test、prod) - 不同业务线隔离(
order-service、user-service)
- 不同环境隔离(
1.2 举例
| Namespace | 说明 |
|---|---|
public | 默认命名空间,所有服务都可以看到 |
dev | 开发环境的服务和配置隔离 |
prod | 生产环境的服务和配置隔离 |
2. Group(分组)
2.1 概念
- 作用:在同一个 Namespace 内,对服务或配置进行进一步分组。
- 避免不同模块或团队的服务/配置混在一起。
- 默认值是
DEFAULT_GROUP。
2.2 举例
假设你在 prod Namespace 下:
| Group | 说明 |
|---|---|
DEFAULT_GROUP | 默认分组,通用服务 |
payment | 支付相关服务 |
user | 用户相关服务 |
3. Service(服务)
3.1 概念
- 作用:一个微服务的逻辑实体。
- 由 多个服务实例(Instance) 组成,每个实例包含 IP、端口、元数据。
- 服务是注册和发现的基本单元。
3.2 举例
假设在 prod Namespace 下 payment Group 内有一个服务:
| Service | 说明 |
|---|---|
order-service | 订单服务 |
payment-service | 支付服务 |
服务实例(Instance)
payment-service 可能有两个实例:
| IP | Port | 元数据 |
|---|---|---|
| 192.168.1.10 | 8080 | |
| 192.168.1.11 | 8080 |
4. 整体关系图
Namespace: prod
└── Group: payment
├── Service: order-service
│ ├── Instance: 192.168.1.10:8080
│ └── Instance: 192.168.1.11:8080
└── Service: payment-service
├── Instance: 192.168.1.20:8080
└── Instance: 192.168.1.21:80804. 总结
- Namespace:跨环境或业务线隔离(大级别隔离)。
- Group:同一个 Namespace 内的服务分组(中级隔离)。
- Service:具体微服务逻辑实体,由实例组成(最小单元)。
Nacos服务领域模型
在上面的数据模式中,我们可以定位到一个服务(Service)了,那么服务的模型又是如何呢?官网提供了下图:
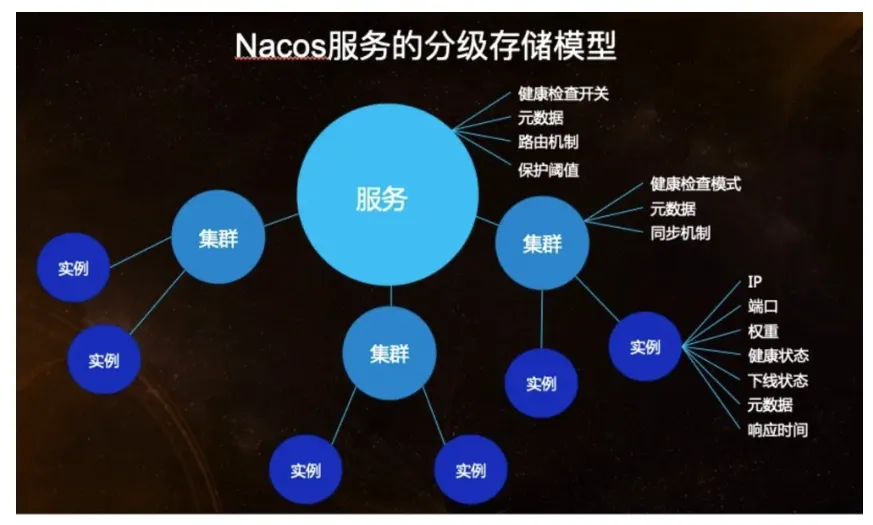
从图中的分级存储模型可以看到,在服务级别,保存了健康检查开关、元数据、路由机制、保护阈值等设置,而集群保存了健康检查模式、元数据、同步机制等数据,实例保存了该实例的ip、端口、权重、健康检查状态、下线状态、元数据、响应时间。
此时,我们忽略掉一对多的情况,整个Nacos中数据存储的关系如下图:
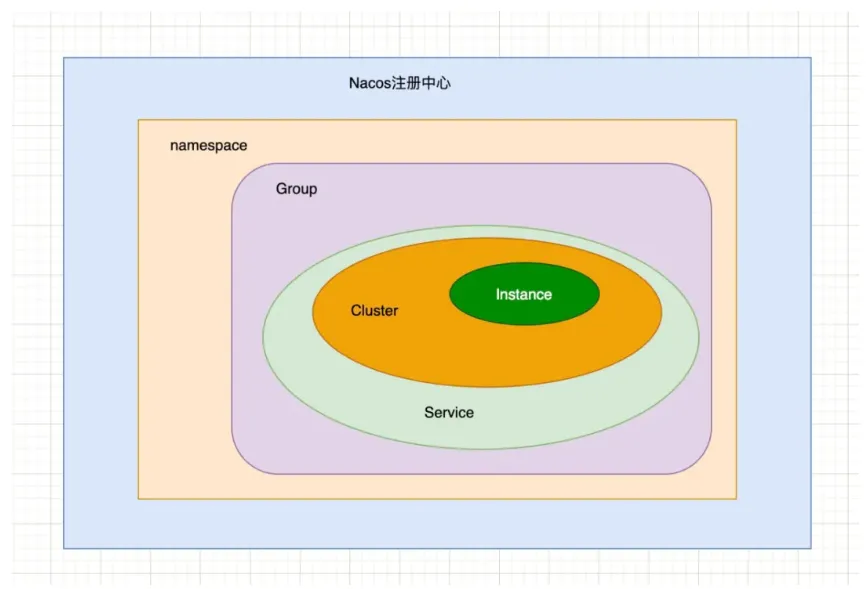
可以看出,整个层级的包含关系为Namespace包含多个Group、Group可包含多个Service、Service可包含多个Cluster、Cluster中包含Instance集合。
对应的部分源码如下:
// ServiceManager类,Map(namespace, Map(group::serviceName, Service))
private final Map<String, Map<String, Service>> serviceMap = new ConcurrentHashMap<>();
// Service类,Map(cluster,Cluster)
private Map<String, Cluster> clusterMap = new HashMap<>();
// Cluster类
private Set<Instance> persistentInstances = new HashSet<>();
private Set<Instance> ephemeralInstances = new HashSet<>();
// Instance类
private String instanceId;
private String ip;
private int port;
private double weight = 1.0D;
//...其中,实例又分为临时实例和持久化实例。它们的区别关键是健康检查的方式。临时实例使用客户端上报模式,而持久化实例使用服务端反向探测模式。
临时实例需要能够自动摘除不健康实例,而且无需持久化存储实例。持久化实例使用服务端探测的健康检查方式,因为客户端不会上报心跳,自然就不能去自动摘除下线的实例。