
微服务之服务发现
为什么要使用服务发现功能?
当调用REST API 或Thrift API的服务时,我们在构建请求时通常需要知道服务实例的IP和端口。在传统应用中,服务实例的地址信息相对固定,可以从配置文件中读取。而这些地址也只是只会偶尔更新。
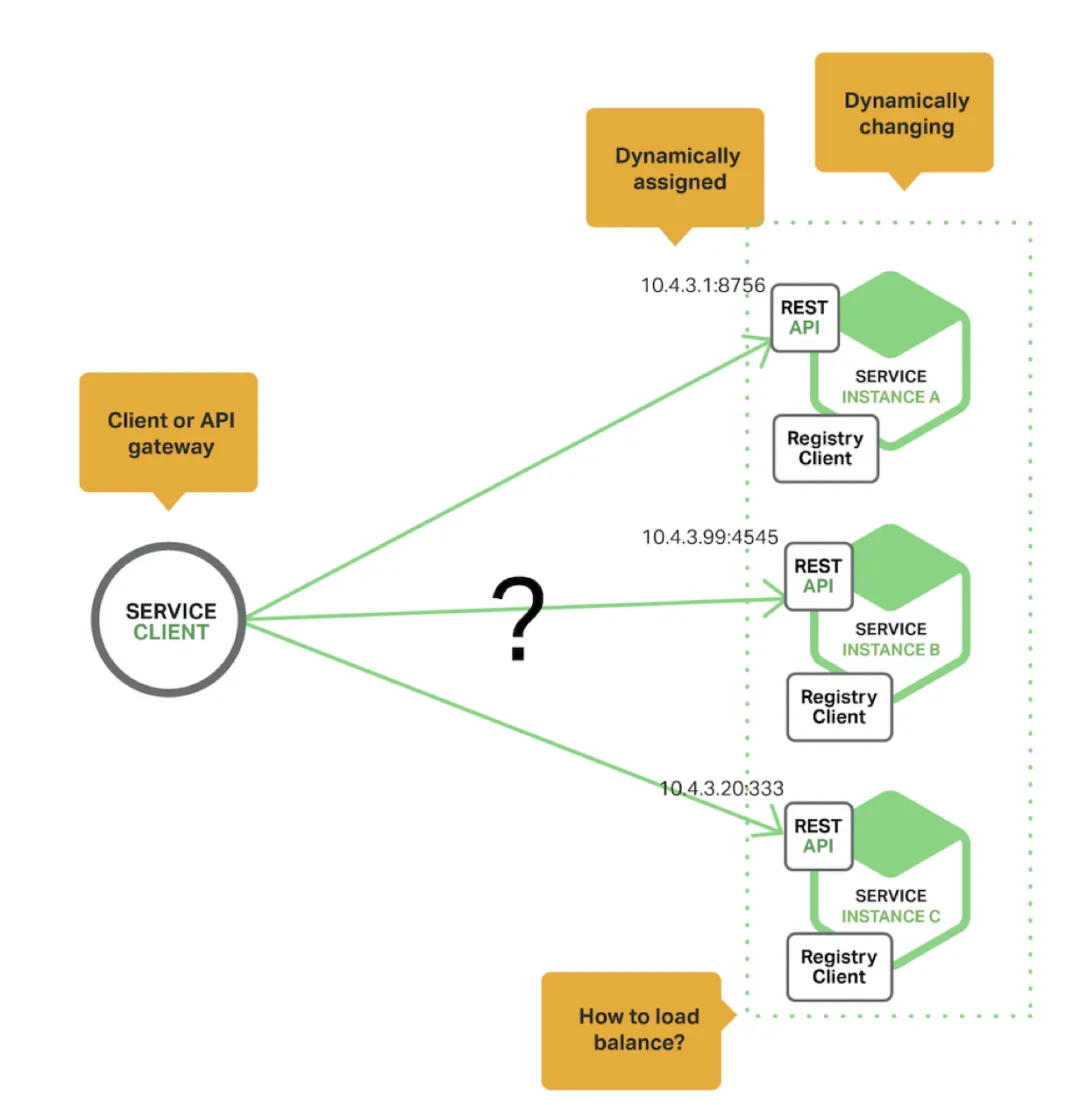
但在现代应用程序中,往往是基于云的微服务架构,此时获取服务实例的IP和端口便是一个需要解决的难题。如下图所示:
上图中,服务实例实例的IP是动态分配。同时,还面临着服务的增减、故障以及升级等变化。这对于客户端程序来说,就需要使用更精确的服务发现机制。
目前,服务发现模式主要有两种:客户端发现模式和服务端发现模式。先来看一下客户端发现模式。
客户端发现模式
使用客户端发现模式时,客户端负责判断服务实例的可用性和请求的负载均衡。服务实例存储在注册表中,也就是说注册表是服务实例的数据库。客户端通过查询服务注册表,获得服务实例列表,然后使用负载均衡算法从中选择一个,然后发起请求。
下图为这种模式的架构图:
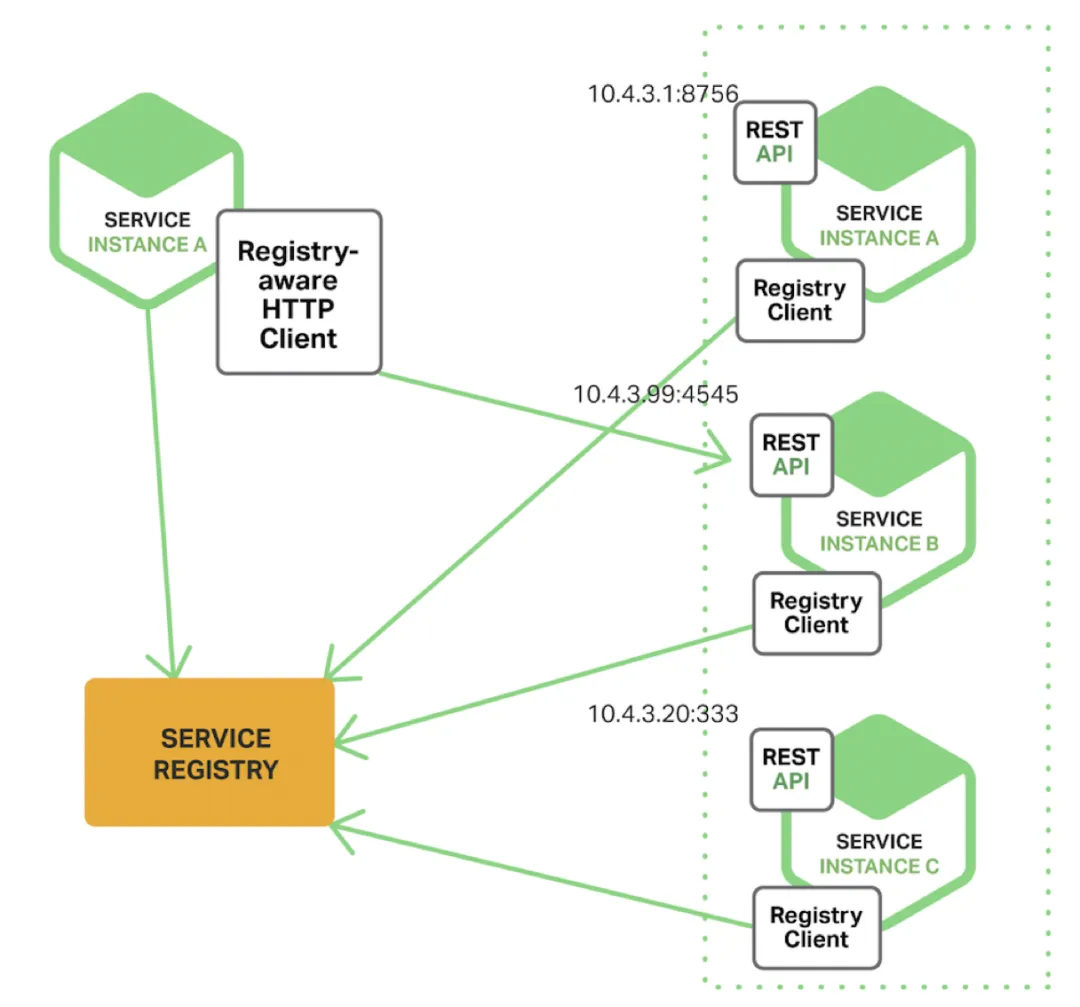
此种模式下,当服务实例启动时,会将自己的地址信息注册到服务注册表,当服务停止时从服务注册表中移除。这期间,通常使用心跳机制来定刷新服务实例的注册。
Netflix Eureka就是一个服务注册表组件,它提供了基于REST API的服务实例注册和查询功能。Netflix Ribbon是一个IPC客户端,可配合Eureka实现对服务实例请求的负载均衡。
客户端发现模式的优点是相对简单,除服务注册表外,不需要其他部分做改动。同时,由于客户端知道所有的可用实例,可以做出更明智的、基于特定应用场景的负载均衡决策,比如使用一致性哈希算法。这种模式的缺点是将客户端和服务注册表功能耦合在了一起,必须为每种编程语言和框架的客户端实现服务发现逻辑。
缺点可能听起来晦涩难懂,现在让我为你举一个例子说明。
缺点解释
缺点主要是 耦合性和实现复杂度高:
- 客户端必须直接跟注册中心打交道
- 每个客户端都要写一套「获取服务列表 + 选择实例」的逻辑。
- 如果你有 Java、Python、Go 三种语言的客户端,都要分别实现一套。
- 更新和维护麻烦
- 如果注册中心协议改了(比如从 HTTP 改成 gRPC),所有客户端代码都得改。
- 如果要增加新特性(比如加权路由、蓝绿发布),也要修改所有客户端。
- 一致性风险
- 每个客户端实现的负载均衡策略可能不一致。
- 有些客户端可能缓存了过时的实例信息,导致调用失败。
举个例子
假设有一个电商系统:
- 服务 A:订单服务
- 服务 B:库存服务
- 注册中心:Nacos
采用 客户端发现模式:
- Java客户端调用库存服务
- Java里用 Ribbon(Spring Cloud 组件)来从 Nacos 获取 B 的实例列表,然后自己做负载均衡。
- Python客户端调用库存服务
- Python里要单独实现一套逻辑,比如调用 Nacos API 拉取实例,再写个轮询负载均衡算法。
- Go客户端调用库存服务
- Go语言也得再写一套发现逻辑。
问题出现了
某天运维同学在 Nacos 里 新增了一个权重路由策略(例如:让「库存服务的实例1」只处理 20% 请求,「实例2」处理 80% 请求)。
- Java 客户端更新了 SDK,支持权重路由。
- 但 Python、Go 客户端没有更新,仍然用轮询。
- 结果就出现:
- Java调用分布正常(20/80)。
- Python和Go调用分布混乱(50/50)。
- 库存实例1压力太大,最终崩溃。
这就是所谓「客户端和注册中心耦合,导致不同语言实现不一致」的问题。
服务器端发现模式
另外一种服务发现模式就是服务器发现模式。下图中展示了该模式的结构:
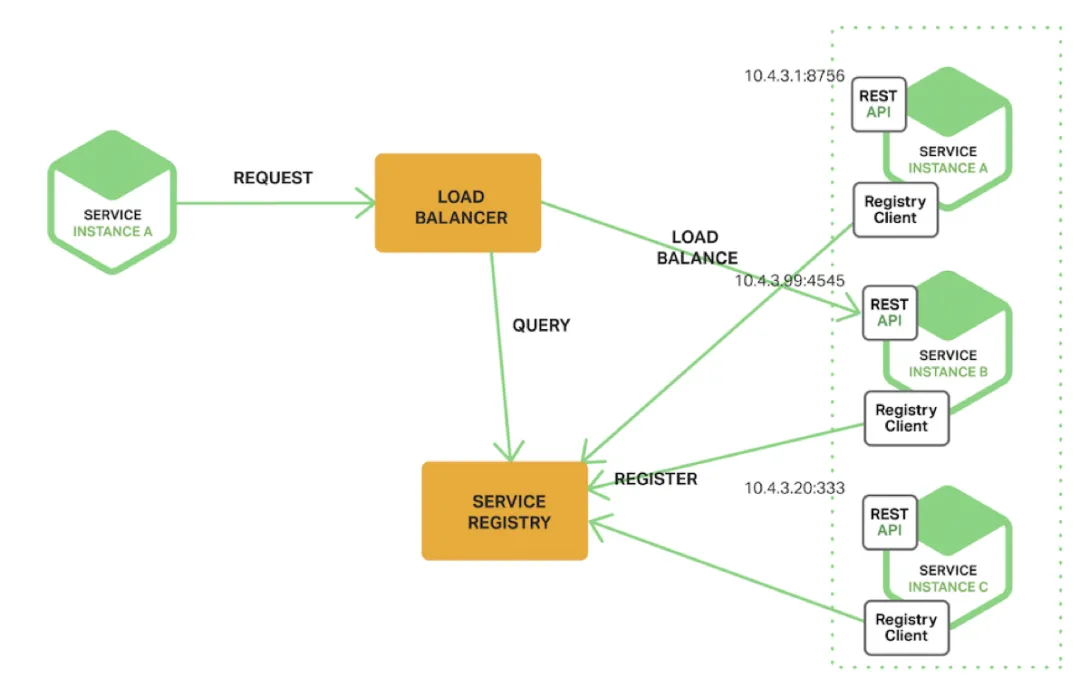
客户端通过负载均衡器向服务发起请求,负载均衡器查询服务注册表,并将请求路由到可用的服务实例。与客户端发现相比,服务实例是通过服务注册表进行注册和注销的。
AWS的ELB(Elastic Load Balancer)就是服务器端发现路由器的示例。ELB通常用于负载均衡来自外网的流量,但你也可以使用ELB来负载均衡私有云(VPV)内部的流量。客户端使用DNS名称,通过ELB发送请求(Http或TCP),ELB在已注册的弹性计算云(EC2)实例或EC2容器服务(ECS)的容器之间进行负载均衡。这种实现并没有单独的服务注册表,而是将EC2实例和ECS容器注册到ELB自身上。
Http服务器和负载均衡器(比如,Nginx plus和Nginx)也可以用作服务器端发现的负载均衡器。比如,使用Consul模板动态配置Nginx反向代理。Consul可以从存储在Consul服务注册表中的配置数据中定时重新生成任意配置文件。每当文件改变时,可以运行一个任意shell命令。比如,Consul模板生成一个nginx.conf文件,用于配置反向代理,然后执行命令告诉Nginx去重新加载配置。
某些部署环境(例如Kubernetes和Marathon)会在集群中的每个主机上运行一个代理。这个代理扮演服务器端发现负载平衡器的角色。客户端向服务发出请求时,会通过代理进行路由,透明地将请求转发到集群中某个服务实例。
服务器端发现模式最大的优点是,服务发现的实现细节从客户端抽离出来了,客户端只用发送请求到负载均衡器即可。这样就无需为每种编程语言和框架的客户端实现服务发现逻辑。而且,某些部署环境已经免费提供了该功能。当然,这种模式也有一些缺点,如果部署环境未提供负载均衡器,你还需要搭建和管理一个额外的高可用系统组件。
两者区别
服务端发现模式简介
- 核心思想:客户端只知道 服务名,不知道具体实例;服务端(通常是网关或负载均衡器) 负责从注册中心获取实例列表并做负载均衡。
- 客户端实现简单:不需要实现服务发现和负载均衡逻辑。
- 负载均衡集中管理:策略统一、更新方便。
区别于客户端发现模式
| 特性 | 客户端发现 | 服务端发现 |
|---|---|---|
| 谁做负载均衡 | 客户端 | 服务端(网关/代理) |
| 客户端复杂度 | 高,每种语言都要实现发现逻辑 | 低,客户端只关心服务名 |
| 灵活性 | 高,可以做自定义策略(比如一致性哈希) | 中,策略由网关统一控制 |
| 多语言支持 | 每种语言都要实现 | 各语言客户端都一样,统一调用网关即可 |
| 更新策略成本 | 高 | 低 |
举个例子
场景
- 服务 A:订单服务
- 服务 B:库存服务
- 注册中心:Nacos
1️⃣ 客户端发现模式
- Java 客户端调用库存服务:
- Java客户端向 Nacos 拉取库存服务实例列表
- 自己选择一个实例做负载均衡(轮询/随机/一致性哈希)
- Python客户端调用库存服务:
- 也得实现一套拉取实例和负载均衡逻辑
问题:每种语言都要实现服务发现逻辑,策略可能不一致。
2️⃣ 服务端发现模式
- Java/Python客户端:
- 只发请求给网关或负载均衡器:
http://gateway/stock-service/api/...
- 只发请求给网关或负载均衡器:
- 网关/负载均衡器:
- 查询 Nacos 获取库存服务的实例列表
- 根据统一策略(轮询/权重)选择实例
- 转发请求到对应实例
好处:
- 客户端完全不用管实例信息。
- 更新负载均衡策略只需修改网关配置,所有客户端立即生效。
- 各语言客户端一致,运维更方便。
简单理解:
- 客户端发现:客户端像“自己去菜市场挑菜”,自己选哪家服务实例。
- 服务端发现:客户端像“告诉餐厅我想吃什么”,餐厅(网关)帮你挑菜。
服务注册表
服务注册表是服务发现的关键,它是一个包含服务实例地址信息的数据库。服务注册表需要具有高可用性和实时更新性。客户端可以缓存从注册表获得的服务实例地址信息。但这些信息会过时,因此,服务注册表也需要是集群模式,且集群之间还需要通过协议维持一致性。
Netflix Eureka是一个服务注册表组件,它提供了基于REST API形式的服务实例注册和查询功能。一个服务实例可以通过POST请求将自己注册到注册表中;可以通过PUT请求,每隔30秒刷新它的注册信息;可以通过Http的DELETE请求或超时机制来删除实例的注册信息;可以使用Http的GET请求来检索注册的服务实例。
常见的服务注册表组件有:etcd、Consul、Apache Zookeeper、Nacos等。
服务注册的选项
服务实例必须通过注册表进行注册或注销,通常有几种不同方式来处理注册和注销。一种是服务实例自己注册,即自我注册模式;另一种是基于其他系统组件来管理服务实例的注册,即第三方注册模式。先来看一下自我注册模式。
自我注册模式
当使用自我注册模式时,服务实例负责在服务注册表中进行自身的注册和注销。如果需要,服务实例还需要发送心跳请求以避免因超时而被注销。下图展示了这种模式的结构图:
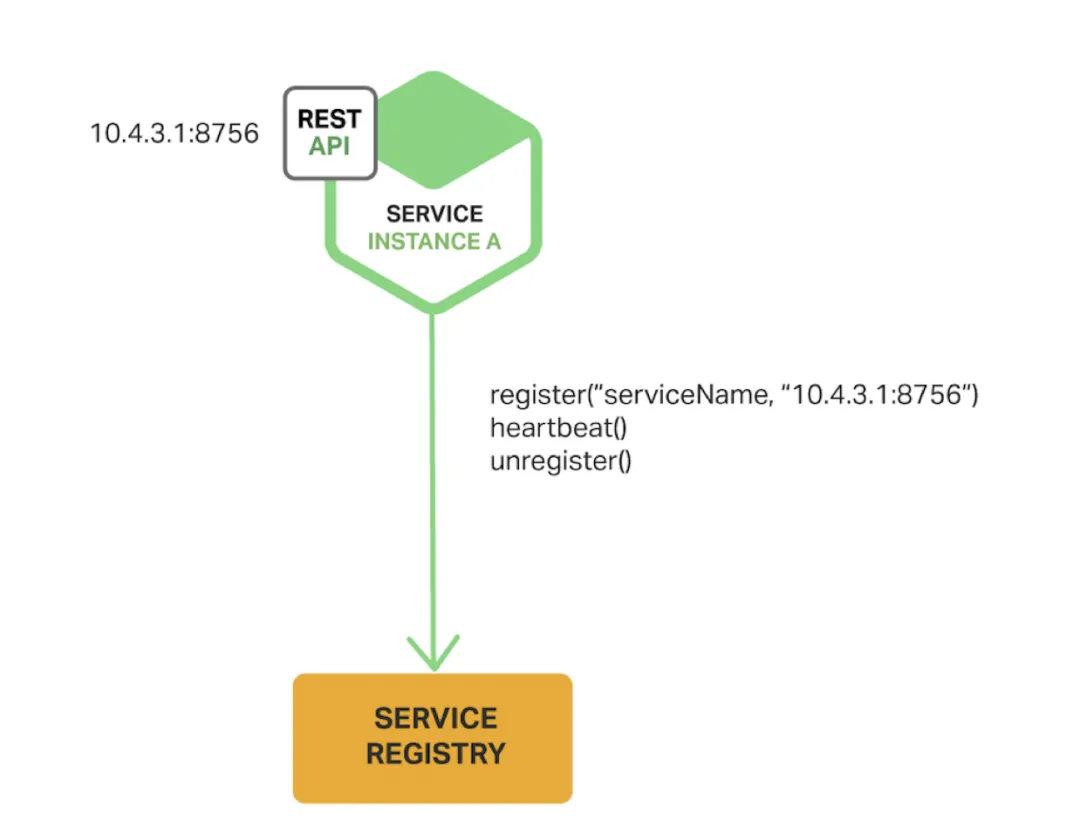
Netflix OSS Eureka客户端就是这种模式的示例,Eureka客户端负责处理服务实例所有的注册和注销事项。在Spring Cloud项目中,实现了包括服务发现的各种模式,基于此可以很轻松的实现自动注册服务实例到Eureka。你只需在Java配置类上使用@EnableEurekaClient注解即可。
自我注册模式的优点是使用起来非常简单,不需要任何其他系统组件。缺点是服务实例与服务注册表紧密耦合,需要在每种编程语言和框架中实现注册功能。
另外一种方式可以让服务和注册表解耦的方式就是第三方注册模式。
第三方注册模式
当使用第三方注册模式时,服务实例不再负责将自己注册到服务注册表。这一功能由第三方组件作为服务注册商来处理。服务注册商通过轮询或订阅事件来跟踪实例的变化。当发现新的可用服务实例时,会将服务实例注册到服务注册表中。同时,也会注销已经停止的服务实例。
下图展示了这种模式的结构:
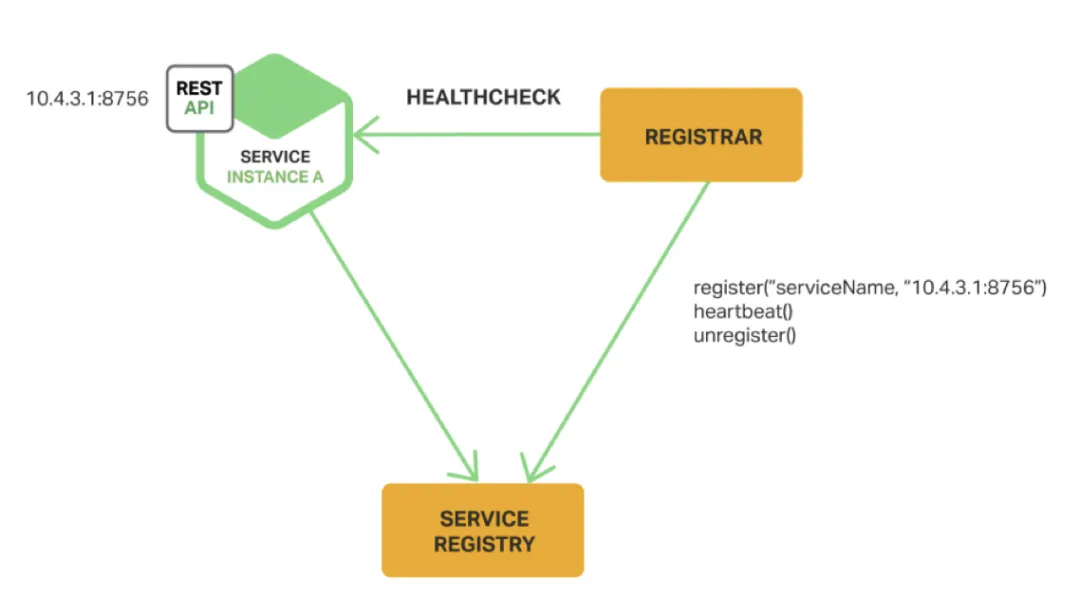
开源项目Registrator便是一个示例,它可以基于Docker容器自动注册和注销服务实例。Registrator支持多种注册表,包括etcd和Consul。
NetflixOSS Prana项目是另外一个示例,它主要用于非JVM语言编写的服务,是与服务实例并行的Sidecar应用程序。Prana基于Netflix Eureka注册和注销服务实例。
第三方注册模式的优点是服务与服务注册表分离,无需每种编程语言和框架的客户端实现服务注册逻辑,而是在专用服务内以集中方式处理服务实例注册。这种模式缺点是,除非部署环境提供内置服务,否则还需要额外搭建和管理一个高度可用的系统组件。